Projecting infectious disease incidence: a COVID-19 example
James Azam, Sebastian Funk
Source:vignettes/projecting_incidence.Rmd
projecting_incidence.RmdNote
bpmodels is now retired and will no longer be maintained. We recommend using
{epichains}instead. If you need help converting your code to use epichains, please open a discussion on epichains.
Overview
Branching processes can be used to project infectious disease trends
in time provided we can characterise the distribution of times between
the symptom onset of successive cases (serial interval), and the
distribution of secondary cases produced by a single individual
(offspring distribution). Such simulations can be achieved in
bpmodels with the chain_sim() function and Pearson et al. (2020), and Abbott et al. (2020) illustrate its application to
COVID-19.
The purpose of this vignette is to use early data on COVID-19 in South Africa (Marivate and Combrink 2020) to illustrate how bpmodels can be used to project incidence in an outbreak.
Let’s load the required packages
Data
Included in bpmodels is a cleaned time series of the first 15 days of the COVID-19 outbreak in South Africa. This can be loaded into memory as follows:
data("covid19_sa", package = "bpmodels")Let us examine the first 6 entries of the dataset.
head(covid19_sa)
#> # A tibble: 6 × 2
#> date cases
#> <date> <int>
#> 1 2020-03-05 1
#> 2 2020-03-07 1
#> 3 2020-03-08 1
#> 4 2020-03-09 4
#> 5 2020-03-11 6
#> 6 2020-03-12 3Setting up the inputs
Onset times
chain_sim() requires a vector of onset times,
t0, for each chain/individual/simulation.
The covid19_sa dataset above is aggregated, so we will
have to disaggregate it into a linelist with each row representing a
case and their onset time.
To achieve this, we will first use the date of the index case as the reference and find the difference between each date and the reference.
days_since_index <- as.integer(covid19_sa$date - min(covid19_sa$date))
days_since_index
#> [1] 0 2 3 4 6 7 8 9 10 11 12 13 14 15Using the vector of start times for the time series, we will then create the linelist by disaggregating the time series so that each case has a corresponding start time.
start_times <- unlist(mapply(
function(x, y) rep(x, times = ifelse(y == 0, 1, y)),
days_since_index,
covid19_sa$cases
))
start_times
#> [1] 0 2 3 4 4 4 4 6 6 6 6 6 6 7 7 7 8 8 8 8 8 8 8 8 9
#> [26] 9 9 9 9 9 9 9 9 9 9 9 9 9 10 10 10 10 10 10 10 10 10 10 10 10
#> [51] 10 11 11 11 11 11 11 11 11 11 11 11 12 12 12 12 12 12 12 12 12 12 12 12 12
#> [76] 12 12 12 12 12 12 12 12 12 12 13 13 13 13 13 13 13 13 13 13 13 13 13 13 13
#> [101] 13 13 13 13 13 13 13 13 13 13 13 13 13 13 13 13 14 14 14 14 14 14 14 14 14
#> [126] 14 14 14 14 14 14 14 14 14 14 14 14 14 14 14 14 14 14 14 14 14 14 14 14 14
#> [151] 15 15 15 15 15 15 15 15 15 15 15 15 15 15 15 15 15 15 15 15 15 15 15 15 15
#> [176] 15 15 15 15 15 15 15 15 15 15 15 15 15 15 15 15 15 15 15 15 15 15 15 15 15
#> [201] 15 15Serial interval
The log-normal distribution is commonly used in epidemiology to characterise quantities such as the serial interval because it has a large variance and can only be positive-valued (Nishiura 2007; Limpert, Stahel, and Abbt 2001).
In this example, we will assume based on COVID-19 literature that the serial interval, S, is log-normal distributed with parameters, \mu = 4.7 and \sigma = 2.9 (Pearson et al. 2020). Note that when the distribution is described this way, it means \mu and \sigma are the expected value and standard deviation of the natural logarithm of the serial interval. Hence, in order to sample the “back-transformed” measured serial interval with expectation/mean, E[S] and standard deviation, SD [S], we can use the following parametrisation:
\begin{align} E[S] &= \ln \left( \dfrac{\mu^2}{(\sqrt{\mu^2 + \sigma^2}} \right) \\ SD [S] &= \sqrt {\ln \left(1 + \dfrac{\sigma^2}{\mu^2} \right)} \end{align}
See “log-normal_distribution” on Wikipedia for a detailed explanation of this parametrisation.
We will now set up the serial interval function with the appropriate
inputs. We adopt R’s random lognormal distribution generator
(rlnorm()) that takes meanlog and
sdlog as arguments, which we define with the
parametrisation above as log_mean() and
log_sd() respectively and wrap it in the
serial_interval() function. Moreover,
serial_interval() takes one argument
sample_size as is required by bpmodels (See
?bpmodels::chain_sim), which is further passed to
rlnorm() as the first argument to determine the number of
observations to sample (See ?rlnorm).
Offspring distribution
The negative binomial distribution is commonly used in epidemiology to account for individual variation in transmissibility, also known as superspreading (Lloyd-Smith et al. 2005).
For this example, we will assume that the offspring distribution is characterised by a negative binomial with R = 2.5 (Abbott et al. 2020) and k = 0.58 (Wang et al. 2020). In this parameterization, R represents the R_0, which is defined as the average number of cases produced by a single individual in an entirely susceptible population. The parameter k represents superspreading, that is, the degree of heterogeneity in transmission by single individuals.
Simulation controls
chain_sim() also requires the end time for the
simulations. For this example, we will simulate outbreaks that end 14
days after the last date of observations in covid19_sa.
#' Date to end simulation (14 day projection in this case)
projection_window <- 14 # 14 days/ 2-week ahead projection
projection_end_day <- max(days_since_index) + projection_window
projection_end_day
#> [1] 29chain_sim() is stochastic, meaning the results are
different every time it is run for the same set of parameters, so we
will run the simulations many times and summarise the results.
We will, therefore, run each simulation 100 times.
#' Number of simulations
sim_rep <- 100Modelling assumptions
chain_sim() makes the following simplifying
assumptions:
- All cases are observed
- There is no reporting delay
- Reporting rate is constant through the course of the epidemic
- No interventions have been implemented
- Population is homogeneous and well-mixed
- All cases start chains of transmission that proceed independently and without competition for or depletion of susceptibles. This implies that none of the cases seen so far have infected each other.
To summarise the whole set up so far, we are going to simulate each chain 100 times, projecting COVID-19 cases over 14 days after the first 15 days.
Running the simulations
We will use the function lapply() to run the simulations
and bind them by rows with dplyr::bind_rows().
set.seed(1234)
sim_chain_sizes <- lapply(
seq_len(sim_rep),
function(sim) {
chain_sim(
n = length(start_times),
offspring = "nbinom",
mu = 2.5,
size = 0.58,
stat = "size",
serial = serial_interval,
t0 = start_times,
tf = projection_end_day,
tree = TRUE
) %>%
mutate(sim = sim)
}
)
sim_output <- bind_rows(sim_chain_sizes)Let us view the first few rows of the simulation results.
head(sim_output)
#> n id ancestor generation time sim
#> 1 1 1 NA 1 0 1
#> 2 2 1 NA 1 2 1
#> 3 3 1 NA 1 3 1
#> 4 4 1 NA 1 4 1
#> 5 5 1 NA 1 4 1
#> 6 6 1 NA 1 4 1Post-processing
Now, we will summarise the simulation results.
We want to plot the individual simulated daily time series and show the median cases per day aggregated over all simulations.
First, we will create the daily time series per simulation by aggregating the number of cases per day of each simulation.
# Daily number of cases for each simulation
incidence_ts <- sim_output %>%
mutate(day = ceiling(time)) %>%
group_by(sim, day) %>%
summarise(cases = n()) %>%
ungroup()
head(incidence_ts)
#> # A tibble: 6 × 3
#> sim day cases
#> <int> <dbl> <int>
#> 1 1 0 1
#> 2 1 2 1
#> 3 1 3 1
#> 4 1 4 4
#> 5 1 6 6
#> 6 1 7 4Next, we will add a date column to the results of each simulation set. We will use the date of the first case in the observed data as the reference start date.
# Get start date from the observed data
index_date <- min(covid19_sa$date)
index_date
#> [1] "2020-03-05"
# Add a dates column to each simulation result
incidence_ts_by_date <- incidence_ts %>%
group_by(sim) %>%
mutate(date = index_date + days(seq(0, n() - 1))) %>%
ungroup()
head(incidence_ts_by_date)
#> # A tibble: 6 × 4
#> sim day cases date
#> <int> <dbl> <int> <date>
#> 1 1 0 1 2020-03-05
#> 2 1 2 1 2020-03-06
#> 3 1 3 1 2020-03-07
#> 4 1 4 4 2020-03-08
#> 5 1 6 6 2020-03-09
#> 6 1 7 4 2020-03-10Now we will aggregate the simulations by day and evaluate the median daily cases across all simulations.
# Median daily number of cases aggregated across all simulations
median_daily_cases <- incidence_ts_by_date %>%
group_by(date) %>%
summarise(median_cases = median(cases)) %>%
ungroup() %>%
arrange(date)
head(median_daily_cases)
#> # A tibble: 6 × 2
#> date median_cases
#> <date> <dbl>
#> 1 2020-03-05 1
#> 2 2020-03-06 1
#> 3 2020-03-07 1
#> 4 2020-03-08 4
#> 5 2020-03-09 4
#> 6 2020-03-10 8Visualization
We will now plot the individual simulation results alongside the median of the aggregated results.
## since all simulations may end at a different date, we will find the minimum
## final date for all simulations for the purposes of visualisation
final_date <- incidence_ts_by_date %>%
group_by(sim) %>%
summarise(final_date = max(date), .groups = "drop") %>%
summarise(min_final_date = min(final_date)) %>%
pull(min_final_date)
incidence_ts_by_date <- incidence_ts_by_date %>%
filter(date <= final_date)
median_daily_cases <- median_daily_cases %>%
filter(date <= final_date)
ggplot(data = incidence_ts_by_date) +
geom_line(
aes(
x = date,
y = cases,
group = sim
),
color = "grey",
linewidth = 0.2,
alpha = 0.25
) +
geom_line(
data = median_daily_cases,
aes(
x = date,
y = median_cases
),
color = "tomato3",
linewidth = 1.8
) +
geom_point(
data = covid19_sa,
aes(
x = date,
y = cases
),
color = "black",
size = 1.75,
shape = 21
) +
geom_line(
data = covid19_sa,
aes(
x = date,
y = cases
),
color = "black",
linewidth = 1
) +
scale_x_continuous(
breaks = seq(
min(incidence_ts_by_date$date),
max(incidence_ts_by_date$date),
5
),
labels = seq(
min(incidence_ts_by_date$date),
max(incidence_ts_by_date$date),
5
)
) +
scale_y_continuous(
breaks = seq(
0,
max(incidence_ts_by_date$cases) + 200,
250
),
labels = seq(
0,
max(incidence_ts_by_date$cases) + 200,
250
)
) +
geom_vline(
mapping = aes(xintercept = max(covid19_sa$date)),
linetype = "dashed"
) +
labs(x = "Date", y = "Daily cases")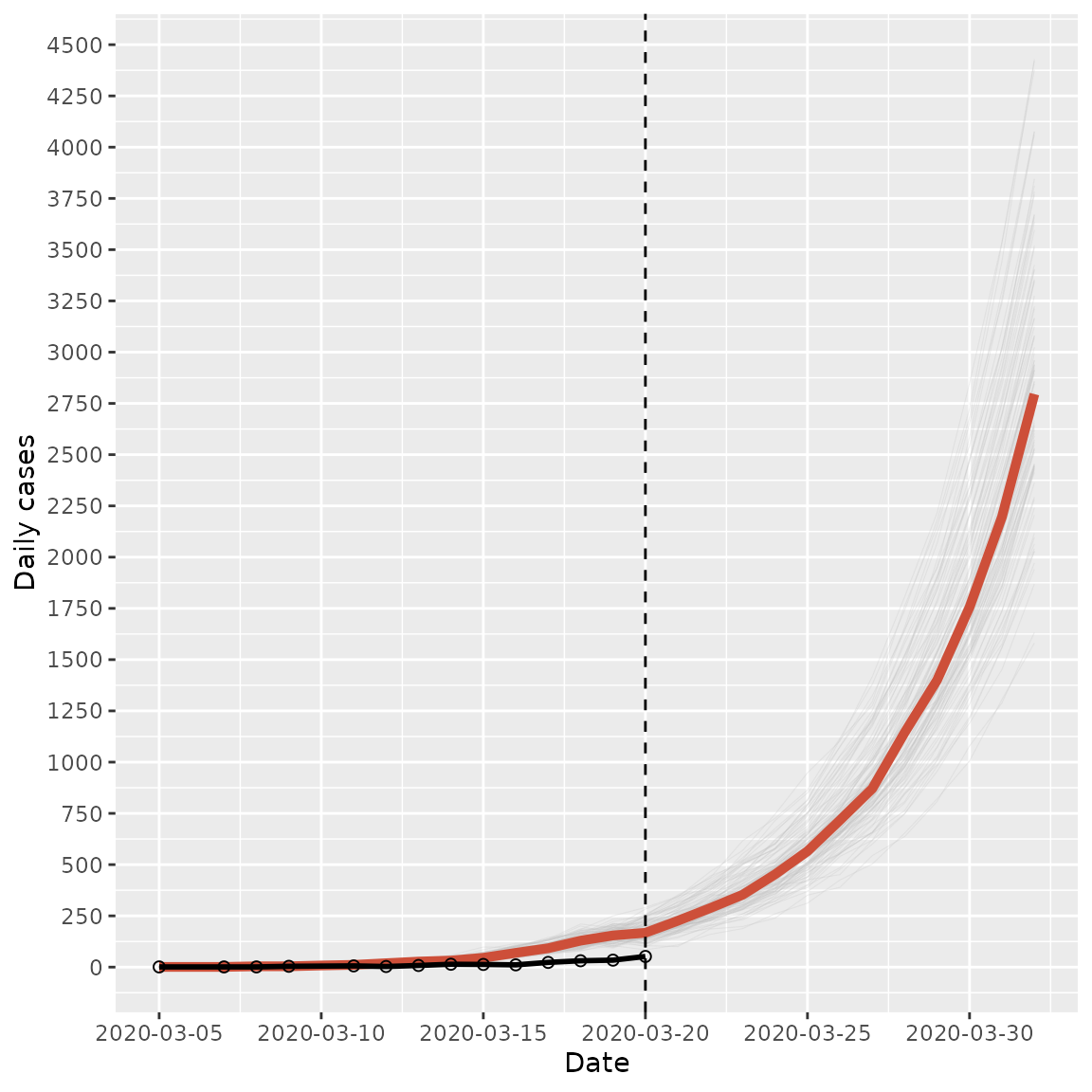
COVID-19 incidence in South Africa projected over a two week window in 2020. The light gray lines represent the individual simulations, the red line represents the median daily cases across all simulations, the black connected dots represent the observed data, and the dashed vertical line marks the beginning of the projection.