Scoring rules in `scoringutils`
Nikos Bosse
2026-07-16
Source:vignettes/scoring-rules.Rmd
scoring-rules.RmdIntroduction
This vignette gives an overview of the default scoring rules made
available through the scoringutils package. You can, of
course, also use your own scoring rules, provided they follow the same
format. If you want to obtain more detailed information about how the
package works, have a look at the revised
version of our scoringutils paper.
We can distinguish two types of forecasts: point forecasts and probabilistic forecasts. A point forecast is a single number representing a single outcome. A probabilistic forecast is a full predictive probability distribution over multiple possible outcomes. In contrast to point forecasts, probabilistic forecasts incorporate uncertainty about different possible outcomes.
Scoring rules are functions that take a forecast and an observation as input and return a single numeric value. For point forecasts, they take the form \(S(\hat{y}, y)\), where \(\hat{y}\) is the forecast and \(y\) is the observation. For probabilistic forecasts, they usually take the form \(S(F, y)\), where \(F\) is the cumulative density function (CDF) of the predictive distribution and \(y\) is the observation. By convention, scoring rules are usually negatively oriented, meaning that smaller values are better (the best possible score is usually zero). In that sense, the score can be understood as a penalty.
Many scoring rules for probabilistic forecasts are so-called (strictly) proper scoring rules. Essentially, this means that they cannot be “cheated”: A forecaster evaluated by a strictly proper scoring rule is always incentivised to report her honest best belief about the future and cannot, in expectation, improve her score by reporting something else. A more formal definition is the following: Let \(G\) be the true, unobserved data-generating distribution. A scoring rule is said to be proper, if under \(G\) and for an ideal forecast \(F = G\), there is no forecast \(F' \neq F\) that in expectation receives a better score than \(F\). A scoring rule is considered strictly proper if, under \(G\), no other forecast \(F'\) in expectation receives a score that is better than or the same as that of \(F\).
Metrics for point forecasts
See a list of the default metrics for point forecasts by calling
get_metrics(example_point).
This is an overview of the input and output formats for point forecasts:
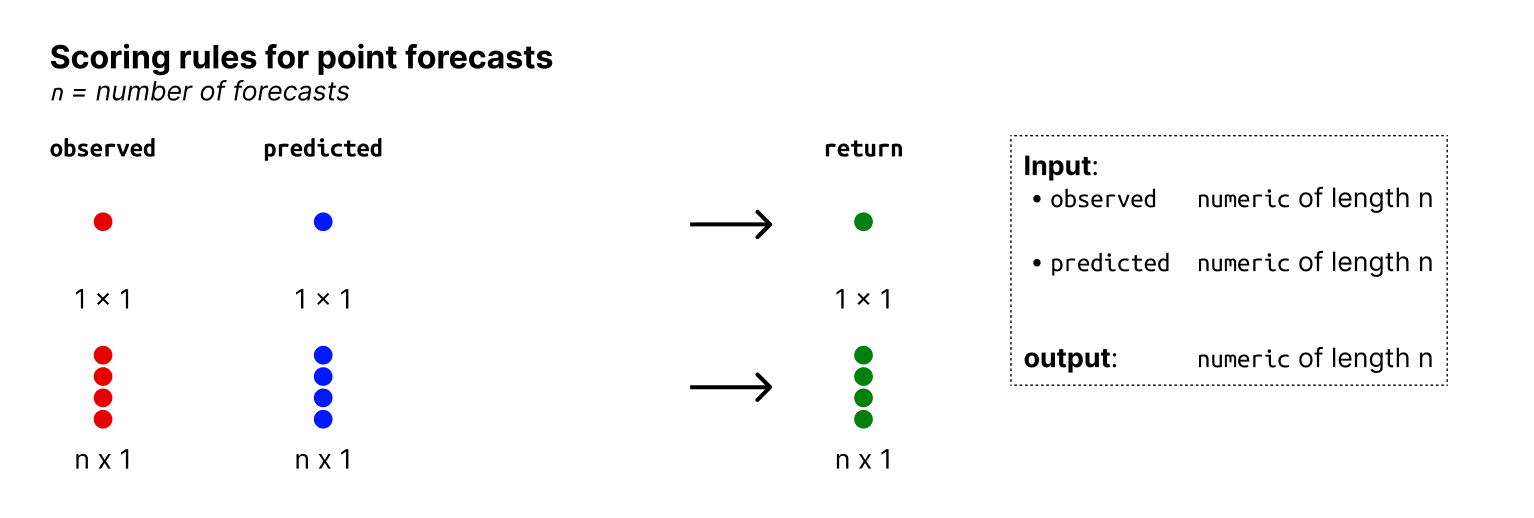
Input and output formats: metrics for point.
A note of caution
Scoring point forecasts can be tricky business. Depending on the choice of the scoring rule, a forecaster who is clearly worse than another, might consistently receive better scores (see Gneiting (2011) for an illustrative example).
Every scoring rule for a point forecast is implicitly minimised by a specific aspect of the predictive distribution. The mean squared error, for example, is only a meaningful scoring rule if the forecaster actually reported the mean of their predictive distribution as a point forecast. If the forecaster reported the median, then the mean absolute error would be the appropriate scoring rule. If the scoring rule and the predictive task do not align, misleading results ensue. Consider the following example:
set.seed(123)
n <- 1000
observed <- rnorm(n, 5, 4)^2
predicted_mu <- mean(observed)
predicted_not_mu <- predicted_mu - rnorm(n, 10, 2)
mean(abs(observed - predicted_mu))
#> [1] 34.45981
mean(abs(observed - predicted_not_mu))
#> [1] 32.54821
mean((observed - predicted_mu)^2)
#> [1] 2171.089
mean((observed - predicted_not_mu)^2)
#> [1] 2290.155Absolute error
Observation: \(y\), a real number
Forecast: \(\hat{y}\), a real number, the median of the forecaster’s predictive distribution.
The absolute error is the absolute difference between the predicted and the observed values.
\[\text{ae} = |y - \hat{y}|\]
The absolute error is only an appropriate rule if \(\hat{y}\) corresponds to the median of the forecaster’s predictive distribution. Otherwise, results will be misleading (see Gneiting (2011)).
Squared error
Observation: \(y\), a real number
Forecast: \(\hat{y}\), a real number, the mean of the forecaster’s predictive distribution.
The squared error is the squared difference between the predicted and the observed values.
\[\text{se} = (y - \hat{y})^2\] The squared error is only an appropriate rule if \(\hat{y}\) corresponds to the mean of the forecaster’s predictive distribution. Otherwise, results will be misleading (see Gneiting (2011)).
Absolute percentage error
Observation: \(y\), a real number
Forecast: \(\hat{y}\), a real number
The absolute percentage error is the absolute percent difference between the predicted and the observed values.
\[\text{ape} = \frac{|y - \hat{y}|}{|y|}\]
The absolute percentage error is only an appropriate rule if \(\hat{y}\) corresponds to the \(\beta\)-median of the forecaster’s predictive distribution with \(\beta = -1\). The \(\beta\)-median, \(\text{med}^{(\beta)}(F)\), is the median of a random variable whose density is proportional to \(y^\beta f(y)\). The specific \(\beta\)-median that corresponds to the absolute percentage error is \(\text{med}^{(-1)}(F)\). Otherwise, results will be misleading (see Gneiting (2011)).
Binary forecasts
See a list of the default metrics for point forecasts by calling
?get_metrics(example_binary).
This is an overview of the input and output formats for point forecasts:
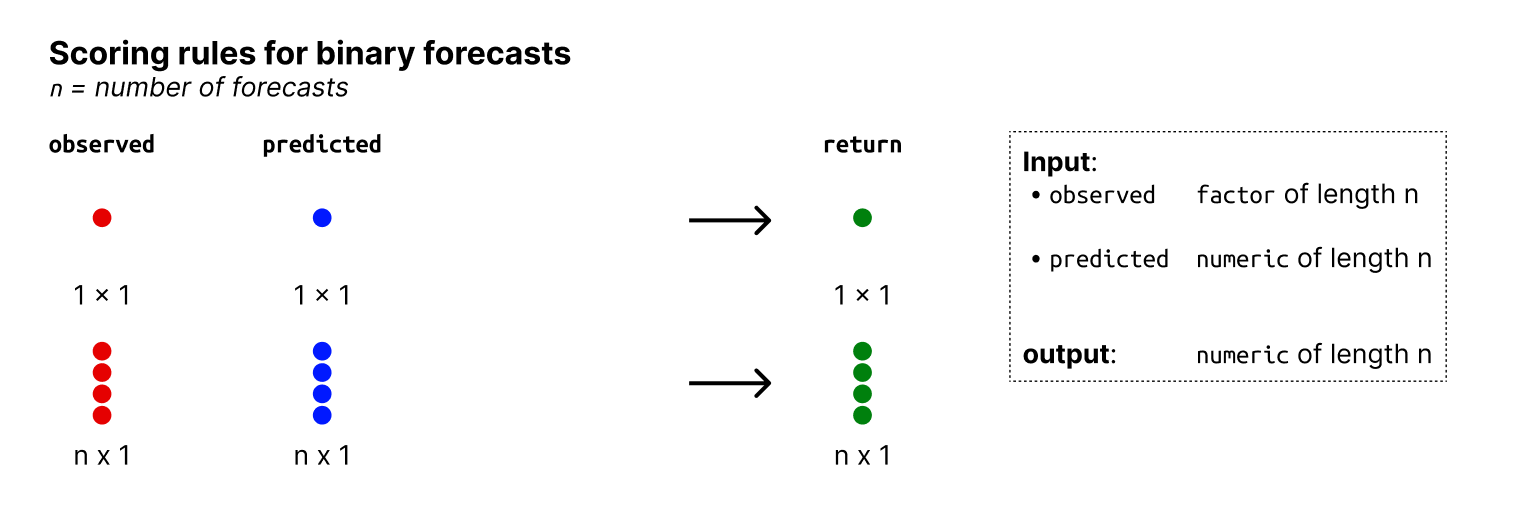
Input and output formats: metrics for binary forecasts.
Brier score
Observation: \(y\), either 0 or 1
Forecast: \(p\), a probability that the observed outcome will be 1.
The Brier score is a strictly proper scoring rule. It is computed as the mean squared error between the probabilistic prediction and the observed outcome.
\[\begin{equation} \text{BS}(p, y) = (p - y)^2 = \begin{cases} p^2, & \text{if } y = 1\\ (1 - p)^2, & \text{if } y = 0 \end{cases} \end{equation}\]
The Brier score and the logarithmic score (see below) differ in how they penalise over- and underconfidence (see Machete (2012)). The Brier score penalises overconfidence and underconfidence in probability space the same. Consider the following example:
n <- 1e6
p_true <- 0.7
observed <- factor(rbinom(n = n, size = 1, prob = p_true), levels = c(0, 1))
p_over <- p_true + 0.15
p_under <- p_true - 0.15
abs(mean(brier_score(observed, p_true)) - mean(brier_score(observed, p_over)))
#> [1] 0.0223866
abs(mean(brier_score(observed, p_true)) - mean(brier_score(observed, p_under)))
#> [1] 0.0226134See ?brier_score() for more information.
Logarithmic score
Observation: \(y\), either 0 or 1
Forecast: \(p\), a probability that the observed outcome will be 1.
The logarithmic score (or log score) is a strictly proper scoring rule. It is computed as the negative logarithm of the probability assigned to the observed outcome.
\[\begin{equation} \text{Log score}(p, y) = - \log(1 - |y - p|) = \begin{cases} -\log (p), & \text{if } y = 1\\ -\log (1 - p), & \text{if } y = 0 \end{cases} \end{equation}\]
The log score penalises overconfidence more strongly than underconfidence (in probability space). Consider the following example:
abs(mean(logs_binary(observed, p_true)) - mean(logs_binary(observed, p_over)))
#> [1] 0.07169954
abs(mean(logs_binary(observed, p_true)) - mean(logs_binary(observed, p_under)))
#> [1] 0.04741833See ?logs_binary() for more information.
Sample-based forecasts
See a list of the default metrics for sample-based forecasts by
calling get_metrics(example_sample_continuous).
This is an overview of the input and output formats for quantile forecasts:
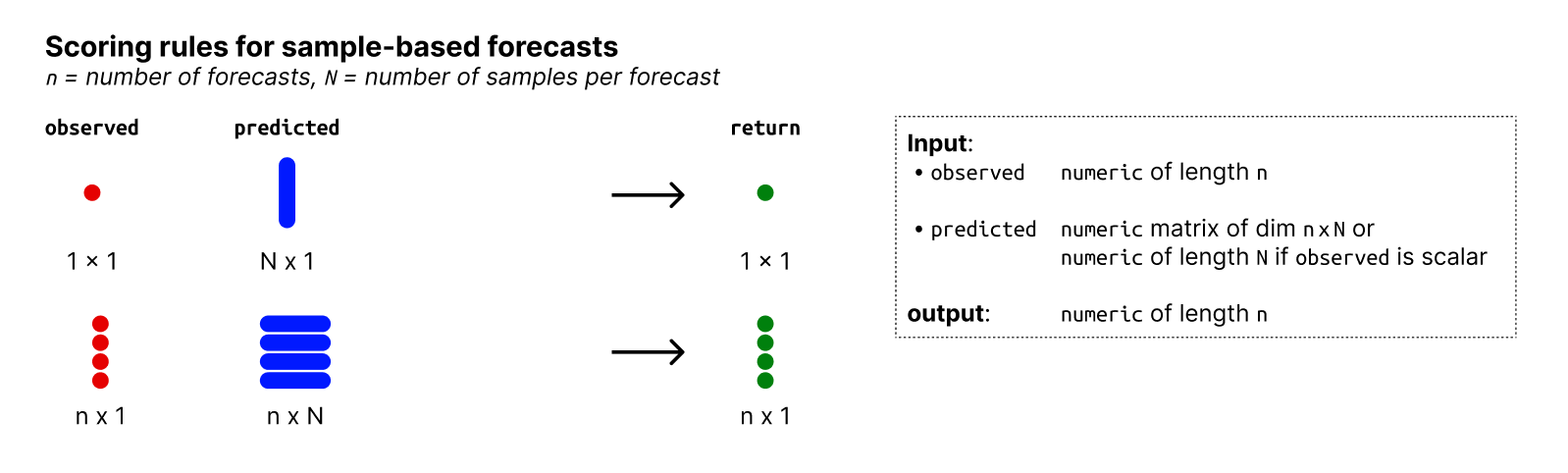
Input and output formats: metrics for sample-based forecasts.
CRPS
Observation: \(y\), a real number (or a discrete number).
Forecast: A continuous (\(F\)) or discrete (\(P\)) forecast.
The continuous ranked probability score (CRPS) is popular in fields such as meteorology and epidemiology. The CRPS is defined as \[\text{CRPS}(F, y) = \int_{-\infty}^\infty \left( F(x) - 1(x \geq y) \right)^2 dx,\] where \(y\) is the observed value and \(F\) the CDF of predictive distribution.
For discrete forecasts, for example count data, the ranked probability score (RPS) can be used instead and is commonly defined as: \[ \text{RPS}(P, y) = \sum_{x = 0}^\infty (P(x) - 1(x \geq y))^2, \] where \(P\) is the cumulative probability mass function (PMF) of the predictive distribution.
The CRPS can be understood as a generalisation of the absolute error to predictive distributions (Gneiting and Raftery 2007). It can also be understood as the integral over the Brier score for the binary probability forecasts implied by the CDF for all possible observed values. The CRPS is also related to the Cramér-distance between two distributions and equals the special case where one of the distributions is concentrated in a single point (see e.g. Ziel (2021)). The CRPS is a global scoring rule, meaning that the entire predictive distribution is taken into account when determining the quality of the forecast.
scoringutils re-exports the crps_sample()
function from the scoringRules package, which assumes that
the forecast is represented by a set of samples from the predictive
distribution. See ?crps_sample() for more information.
Overprediction, underprediction and dispersion
The CRPS can be interpreted as a sum of a dispersion, an overprediction and an underprediction component. If \(m\) is the median forecast then the dispersion component is \[\text{CRPS}(F, m),\] the overprediction component is \[ \begin{cases} m > y & CRPS(F, y) - CRPS(F, m)\\ m \leq y & 0\\ \end{cases} \] and the underprediction component is \[ \begin{cases} m < y & CRPS(F, y) - CRPS(F, m)\\ m \geq y & 0\\ \end{cases} \]
These can be accessed via the dispersion_sample(),
overprediction_sample() and
underprediction_sample() functions, respectively.
Log score
Observation: \(y\), a real number (or a discrete number).
Forecast: A continuous (\(F\)) or discrete (\(P\)) forecast.
The logarithmic scoring rule is simply the negative logarithm of the density of the the predictive distribution evaluated at the observed value:
\[ \text{log score}(F, y) = -\log f(y), \]
where \(f\) is the predictive probability density function (PDF) corresponding to the Forecast \(F\) and \(y\) is the observed value.
For discrete forecasts, the log score can be computed as
\[ \text{log score}(F, y) = -\log p_y, \] where \(p_y\) is the probability assigned to the observed outcome \(y\) by the forecast \(F\).
The logarithmic scoring rule can produce large penalties when the observed value takes on values for which \(f(y)\) (or \(p_y\)) is close to zero. It is therefore considered to be sensitive to outlier forecasts. This may be desirable in some applications, but it also means that scores can easily be dominated by a few extreme values. The logarithmic scoring rule is a local scoring rule, meaning that the score only depends on the probability that was assigned to the actual outcome. This is often regarded as a desirable property for example in the context of Bayesian inference . It implies for example, that the ranking between forecasters would be invariant under monotone transformations of the predictive distribution and the target.
scoringutils re-exports the logs_sample()
function from the scoringRules package, which assumes that
the forecast is represented by a set of samples from the predictive
distribution. One implications of this is that it is currently not
advisable to use the log score for discrete forecasts. The reason for
this is that scoringRules::logs_sample() estimates a
predictive density from the samples, which can be problematic for
discrete forecasts.
See ?logs_sample() for more information.
Dawid-Sebastiani score
Observation: \(y\), a real number (or a discrete number).
Forecast: \(F\). The predictive distribution with mean \(\mu\) and standard deviation \(\sigma\).
The Dawid-Sebastiani score is a proper scoring rule that only relies on the first moments of the predictive distribution and is therefore easy to compute. It is given as
\[\text{dss}(F, y) = \left( \frac{y - \mu}{\sigma} \right)^2 + 2 \cdot \log \sigma.\]
scoringutils re-exports the implementation of the DSS
from the scoringRules package. It assumes that the forecast
is represented by a set of samples drawn from the predictive
distribution. See ?dss_sample() for more information.
Dispersion - Median Absolute Deviation (MAD)
Observation: Not required.
Forecast: \(F\), the predictive distribution.
Dispersion (also called sharpness) is the ability to produce narrow forecasts. It is a feature of the forecasts only and does not depend on the observations. Dispersion is therefore only of interest conditional on calibration: a very precise forecast is not useful if it is clearly wrong.
One way to measure sharpness (as suggested by Funk et al. (2019)) is the normalised median
absolute deviation about the median (MADN) ). It is computed as \[ S(F) = \frac{1}{0.675} \cdot \text{median}(|F -
\text{median(F)}|). \] If the forecast \(F\) follows a normal distribution, then
sharpness will equal the standard deviation of \(F\).For more details, see
?mad_sample().
Bias
Observation: \(y\), a real number (or a discrete number).
Forecast: A continuous (\(F\)) or discrete (\(P\)) forecast.
Bias is a measure of the tendency of a forecaster to over- or
underpredict. For continuous forecasts, the
scoringutils implementation calculates bias as \[B(F, y) = 1 - 2 \cdot F (y), \] where
\(F(y)\) is the empirical cumulative
distribution function of the forecast evaluated at the observed value
\(y\). To handle ties appropriately
(which can occur when predictions equal observations for example due to
rounding), the implementation uses mid-ranks: \(F(y)\) is computed as the proportion of
predictions strictly less than \(y\)
plus half the proportion of predictions equal to \(y\).
For discrete forecasts, we calculate bias as \[B(P, y) = 1 - (P(y) + P(y + 1)). \] where \(P(y)\) is the cumulative probability assigned to all outcomes smaller or equal to \(y\), i.e. the cumulative probability mass function.
Bias is bound between -1 and 1 and represents the tendency of forecasts to be biased rather than the absolute amount of over- and underprediction (which is e.g. the case for the weighted interval score (WIS, see below).
Absolute error of the median
Observation: \(y\), a real number (or a discrete number).
Forecast: A forecast \(F\)
\[\text{ae}_{\text{median}}(F, y) = |\text{median} (F) - y|.\] See section A note of caution or Gneiting (2011) for a discussion on the correspondence between the absolute error and the median.
Squared error of the mean
Observation: \(y\), a real number (or a discrete number).
Forecast: A forecast \(F\)
\[\text{se}_{\text{medn}}(F, y) = (\text{mean} (F) - y)^2.\] See section A note of caution or Gneiting (2011) for a discussion on the correspondence between the squared error and the mean.
Quantile-based forecasts
See a list of the default metrics for quantile-based forecasts by
calling get_metrics(example_quantile).
This is an overview of the input and output formats for quantile forecasts:
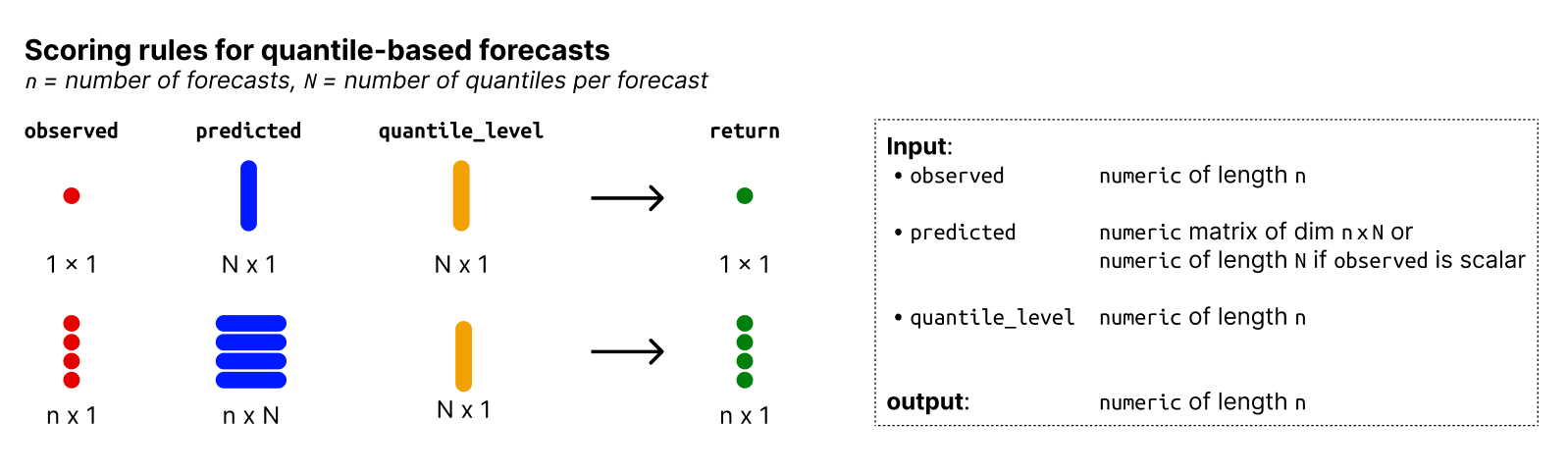
Input and output formats: metrics for quantile-based forecasts.
Weighted interval score (WIS)
Observation: \(y\), a real number
Forecast: \(F\). The CDF of the predictive distribution is represented by a set of quantiles. These quantiles form the lower (\(l\)) and upper (\(u\)) bounds of central prediction intervals.
The weighted interval score (WIS) is a strictly proper scoring rule and can be understood as an approximation of the CRPS for forecasts in a quantile format (which in turn represents a generalisation of the absolute error). Quantiles are assumed to be the lower and upper bounds of prediction intervals symmetric around the median. For a single interval, the interval score is
\[IS_\alpha(F,y) = \underbrace{(u-l)}_\text{dispersion} + \underbrace{\frac{2}{\alpha} \cdot (l-y) \cdot \mathbf{1}(y \leq l)}_{\text{overprediction}} + \underbrace{\frac{2}{\alpha} \cdot (y-u) \cdot \mathbf{1}(y \geq u)}_{\text{underprediction}}, \]
where \(\mathbf{1}()\) is the indicator function, and \(l\) and \(u\) are the \(\frac{\alpha}{2}\) and \(1 - \frac{\alpha}{2}\) quantiles of the predictive distribution \(F\). \(l\) and \(u\) together form the prediction interval. The interval score can be understood as the sum of three components: dispersion, overprediction and underprediction.
For a set of \(K\) prediction intervals and the median \(m\), the score is given as a weighted sum of individual interval scores, i.e.
\[WIS = \frac{1}{K + 0.5} \cdot \left(w_0 \cdot |y - m| + \sum_{k = 1}^{K} w_k \cdot IS_{\alpha_{k}}(F, y)\right),\] where \(m\) is the median forecast and \(w_k\) is a weight assigned to every interval. When the weights are set to \(w_k = \frac{\alpha_k}{2}\) and \(w_0 = 0.5\), then the WIS converges to the CRPS for an increasing number of equally spaced quantiles.
See ?wis() for more information.
Bias
Observation: \(y\), a real number
Forecast: \(F\). The CDF of the predictive distribution is represented by a set of quantiles, \(Q\).
Bias can be measured as
\[\begin{equation} \text{B}(F, y) = \begin{cases} (1 - 2 \cdot \max \{\alpha | q_\alpha \in Q \land q_\alpha \leq y\}), & \text{if } y < q_{0.5} \quad \text{(overprediction)}\\ (1 - 2 \cdot \min \{\alpha | q_\alpha \in Q_t \land q_\alpha \geq y\}, & \text{if } y > q_{0.5} \quad \text{(underprediction)}\\ 0, & \text{if } y = q_{0.5}, \\ \end{cases} \end{equation}\]
where \(q_\alpha\) is the \(\alpha\)-quantile of the predictive distribution. For consistency, we define \(Q\) (the set of quantiles that form the predictive distribution \(F\)) such that it always includes the element \(q_0 = -\infty\) and \(q_1 = \infty\). In clearer terms, bias is:
- \(1 - (2 \times\) the maximum percentile rank for which the corresponding quantile is still below the observed value), if the observed value is smaller than the median of the predictive distribution.
- \(1 - (2 \times\) the minimum percentile rank for which the corresponding quantile is still larger than the observed value) if the observed value is larger than the median of the predictive distribution..
- \(0\) if the observed value is exactly the median.
Bias can assume values between -1 (underprediction) and 1 (overprediction) and is 0 ideally (i.e. unbiased).
For an increasing number of quantiles, the percentile rank will equal the proportion of predictive samples below the observed value, and the bias metric coincides with the one for continuous forecasts (see above).
See ?bias_quantile() for more information.
Interval coverage
Observation: \(y\), a real number
Forecast: \(F\). The CDF of the predictive distribution is represented by a set of quantiles. These quantiles form central prediction intervals.
Interval coverage for a given interval range is defined as the proportion of observations that fall within the corresponding central prediction intervals. Central prediction intervals are symmetric around the median and formed by two quantiles that denote the lower and upper bound. For example, the 50% central prediction interval is the interval between the 0.25 and 0.75 quantiles of the predictive distribution.
Interval coverage deviation
The interval coverage deviation is the difference between the observed interval coverage and the nominal interval coverage. For example, if the observed interval coverage for the 50% central prediction interval is 0.6, then the interval coverage deviation is \(0.6 - 0.5 = 0.1.\)
\[\text{interval coverage deviation} = \text{observed interval coverage} - \text{nominal interval coverage}\]
Absolute error of the median
Observation: \(y\), a real number
Forecast: \(F\). The CDF of the predictive distribution is represented by a set of quantiles.
The absolute error of the median is the absolute difference between the median of the predictive distribution and the observed value.
\[\text{ae}_\text{median} = |\text{median}(F) - y|\] See section A note of caution or Gneiting (2011) for a discussion on the correspondence between the absolute error and the median.
Quantile score
Observation: \(y\), a real number
Forecast: \(F\). The CDF of the predictive distribution is represented by a set of quantiles.
The quantile score, also called pinball loss, for a single quantile level \(\tau\) is defined as
\[\begin{equation} \text{QS}_\tau(F, y) = 2 \cdot \{ \mathbf{1}(y \leq q_\tau) - \tau\} \cdot (q_\tau - y) = \begin{cases} 2 \cdot (1 - \tau) * q_\tau - y, & \text{if } y \leq q_\tau\\ 2 \cdot \tau * |q_\tau - y|, & \text{if } y > q_\tau, \end{cases} \end{equation}\]
with \(q_\tau\) being the \(\tau\)-quantile of the predictive distribution \(F\), and \(\mathbf{1}(\cdot)\) the indicator function.
The (unweighted) interval score (see above) for a \(1 - \alpha\) prediction interval can be computed from the quantile scores at levels \(\alpha/2\) and \(1 - \alpha/2\) as
\[\text{IS}_\alpha(F, y) = \frac{\text{QS}_{\alpha/2}(F, y) + \text{QS}_{1 - \alpha/2}(F, y)}{\alpha}\].
The weighted interval score can be obtained as a simple average of the quantile scores:
\[\text{WIS}_\alpha(F, y) = \frac{\text{QS}_{\alpha/2}(F, y) + \text{QS}_{1 - \alpha/2}(F, y)}{2}\].
See ?quantile_score and Bracher
et al. (2021) for more details.
Additional metrics
Quantile coverage
Quantile coverage for a given quantile level is defined as the proportion of observed values that are smaller than the corresponding predictive quantiles. For example, the 0.5 quantile coverage is the proportion of observed values that are smaller than the 0.5-quantiles of the predictive distribution.