Examples: estimate_infections()
Source:vignettes/estimate_infections_options.Rmd
estimate_infections_options.RmdThe estimate_infections() function encodes a range of
different model options. In this vignette we apply some of these to the
example data provided with the EpiNow2 package, highlighting
differences in inference results and run times. It is not meant as a
comprehensive exploration of all the functionality in the package, but
intended to give users a flavour of the kind of model options that exist
for reproduction number estimation and forecasting within the package,
and the differences in computational speed between them. For
mathematical detail on the model please consult the model definition vignette, and for a
more general description of the use of the function, the estimate_infections
workflow vignette.
Set up
We first load the EpiNow2 package and also the rstan package that we will use later to show the differences in run times between different model options.
library("EpiNow2")
#>
#> Attaching package: 'EpiNow2'
#> The following object is masked from 'package:stats':
#>
#> Gamma
library("rstan")
#> Loading required package: StanHeaders
#>
#> rstan version 2.32.7 (Stan version 2.32.2)
#> For execution on a local, multicore CPU with excess RAM we recommend calling
#> options(mc.cores = parallel::detectCores()).
#> To avoid recompilation of unchanged Stan programs, we recommend calling
#> rstan_options(auto_write = TRUE)
#> For within-chain threading using `reduce_sum()` or `map_rect()` Stan functions,
#> change `threads_per_chain` option:
#> rstan_options(threads_per_chain = 1)In this examples we set the number of cores to use to 4 but the optimal value here will depend on the computing resources available.
options(mc.cores = 4)Data
We will use an example data set that is included in the package, representing an outbreak of COVID-19 with an initial rapid increase followed by decreasing incidence.
library("ggplot2")
reported_cases <- example_confirmed[1:60]
ggplot(reported_cases, aes(x = date, y = confirm)) +
geom_col() +
theme_minimal() +
xlab("Date") +
ylab("Cases")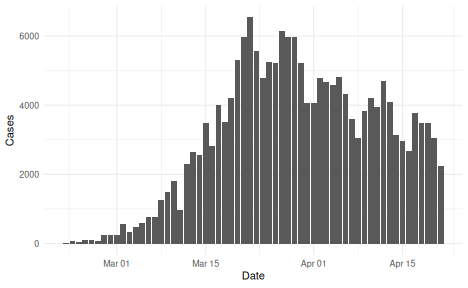
Parameters
Before running the model we need to decide on some parameter values, in particular any delays, the generation time, and a prior on the initial reproduction number.
Delays: incubation period and reporting delay
Delays reflect the time that passes between infection and reporting, if these exist. In this example, we assume two delays, an incubation period (i.e. delay from infection to symptom onset) and a reporting delay (i.e. the delay from symptom onset to being recorded as a symptomatic case). These delays are usually not the same for everyone and are instead characterised by a distribution. For the incubation period we use an example from the literature that is included in the package.
example_incubation_period
#> - lognormal distribution (max: 14):
#> meanlog:
#> - normal distribution:
#> mean:
#> 1.6
#> sd:
#> 0.064
#> sdlog:
#> - normal distribution:
#> mean:
#> 0.42
#> sd:
#> 0.069For the reporting delay, we use a lognormal distribution with mean of
2 days and standard deviation of 1 day. Note that the mean and standard
deviation must be converted to the log scale, which can be done using
the convert_log_logmean() function.
reporting_delay <- LogNormal(mean = 2, sd = 1, max = 10)
reporting_delay
#> - lognormal distribution (max: 10):
#> meanlog:
#> 0.58
#> sdlog:
#> 0.47EpiNow2 provides a feature that allows us to combine these delays into one by summing them up
delay <- example_incubation_period + reporting_delay
delay
#> Composite distribution:
#> - lognormal distribution (max: 14):
#> meanlog:
#> - normal distribution:
#> mean:
#> 1.6
#> sd:
#> 0.064
#> sdlog:
#> - normal distribution:
#> mean:
#> 0.42
#> sd:
#> 0.069
#> - lognormal distribution (max: 10):
#> meanlog:
#> 0.58
#> sdlog:
#> 0.47Generation time
If we want to estimate the reproduction number we need to provide a distribution of generation times. Here again we use an example from the literature that is included with the package.
example_generation_time
#> - gamma distribution (max: 14):
#> shape:
#> - normal distribution:
#> mean:
#> 1.4
#> sd:
#> 0.48
#> rate:
#> - normal distribution:
#> mean:
#> 0.38
#> sd:
#> 0.25Initial reproduction number
Lastly we need to choose a prior for the initial value of the reproduction number. This is assumed by the model to be normally distributed and we can set the mean and the standard deviation. We decide to set the mean to 2 and the standard deviation to 1.
rt_prior <- LogNormal(mean = 2, sd = 1)Running the model
We are now ready to run the model and will in the following show a number of possible options for doing so.
Default options
By default the model uses a renewal equation for infections and a Gaussian Process prior for the reproduction number. Putting all the data and parameters together and tweaking the Gaussian Process to have a shorter length scale prior than the default we run.
def <- estimate_infections(reported_cases,
generation_time = gt_opts(example_generation_time),
delays = delay_opts(delay),
rt = rt_opts(prior = rt_prior)
)
# summarise results
summary(def)
#> measure estimate
#> <char> <char>
#> 1: New infections per day 2226 (1352 -- 3716)
#> 2: Expected change in reports Likely decreasing
#> 3: Effective reproduction no. 0.89 (0.7 -- 1.1)
#> 4: Rate of growth -0.03 (-0.097 -- 0.039)
#> 5: Doubling/halving time (days) -23 (18 -- -7.1)
# elapsed time (in seconds)
get_elapsed_time(def$fit)
#> warmup sample
#> chain:1 43.414 13.293
#> chain:2 40.129 16.888
#> chain:3 35.367 17.262
#> chain:4 26.508 20.997
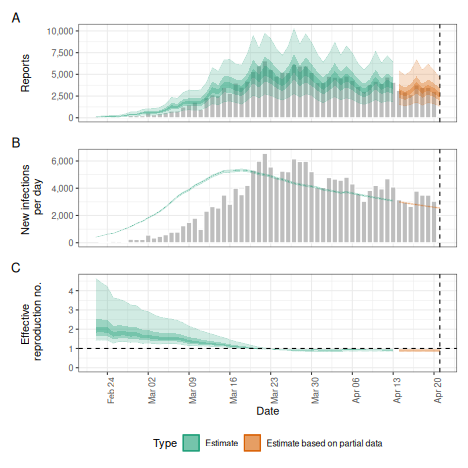
# summary plot
plot(def)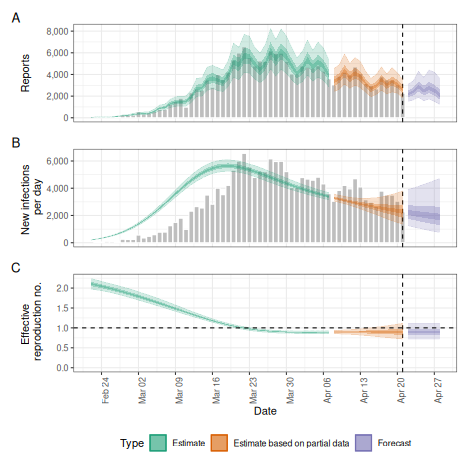
Reducing the accuracy of the approximate Gaussian Process
To speed up the calculation of the Gaussian Process we could decrease its accuracy, e.g. decrease the proportion of time points to use as basis functions from the default of 0.2 to 0.15.
agp <- estimate_infections(reported_cases,
generation_time = gt_opts(example_generation_time),
delays = delay_opts(delay),
rt = rt_opts(prior = rt_prior),
gp = gp_opts(basis_prop = 0.15)
)
#> Warning: There were 2 divergent transitions after warmup. See
#> https://mc-stan.org/misc/warnings.html#divergent-transitions-after-warmup
#> to find out why this is a problem and how to eliminate them.
#> Warning: Examine the pairs() plot to diagnose sampling problems
# summarise results
summary(agp)
#> measure estimate
#> <char> <char>
#> 1: New infections per day 2240 (1367 -- 3613)
#> 2: Expected change in reports Likely decreasing
#> 3: Effective reproduction no. 0.89 (0.71 -- 1.1)
#> 4: Rate of growth -0.03 (-0.095 -- 0.034)
#> 5: Doubling/halving time (days) -23 (21 -- -7.3)
# elapsed time (in seconds)
get_elapsed_time(agp$fit)
#> warmup sample
#> chain:1 34.423 17.192
#> chain:2 35.619 11.553
#> chain:3 31.019 10.938
#> chain:4 35.983 17.680
# summary plot
plot(agp)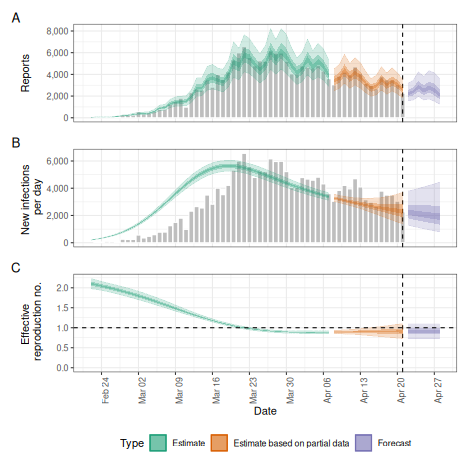
Adjusting for future susceptible depletion
We might want to adjust for future susceptible depletion. Here, we do so by setting the population to 1000000 and projecting the reproduction number from the latest estimate (rather than the default, which fixes the reproduction number to an earlier time point based on the given reporting delays). Note that this only affects the forecasts and is done using a crude adjustment (see the model definition).
dep <- estimate_infections(reported_cases,
generation_time = gt_opts(example_generation_time),
delays = delay_opts(delay),
rt = rt_opts(
prior = rt_prior,
pop = Normal(mean = 1000000, sd = 1000), future = "latest"
)
)
# summarise results
summary(dep)
#> measure estimate
#> <char> <char>
#> 1: New infections per day 2208 (1326 -- 3686)
#> 2: Expected change in reports Likely decreasing
#> 3: Effective reproduction no. 0.89 (0.71 -- 1.1)
#> 4: Rate of growth -0.031 (-0.098 -- 0.038)
#> 5: Doubling/halving time (days) -23 (18 -- -7.1)
# elapsed time (in seconds)
get_elapsed_time(dep$fit)
#> warmup sample
#> chain:1 53.613 13.798
#> chain:2 43.953 20.774
#> chain:3 55.159 16.359
#> chain:4 44.106 18.498
# summary plot
plot(dep)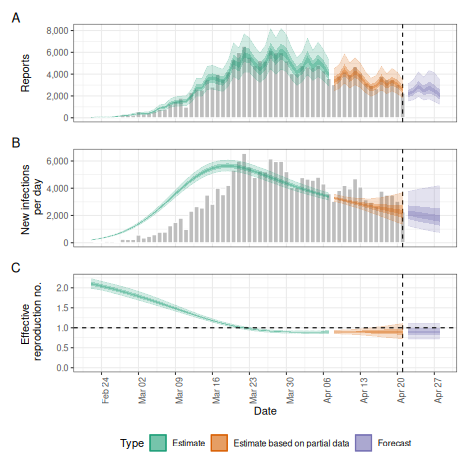
Adjusting for truncation of the most recent data
We might further want to adjust for right-truncation of recent data estimated using the estimate_truncation model. Here, instead of doing so we assume that we know about truncation with mean of 1/2 day, sd 1/2 day, following a lognormal distribution and with a maximum of three days.
trunc_dist <- LogNormal(
mean = 0.5,
sd = 0.5,
max = 3
)
trunc_dist
#> - lognormal distribution (max: 3):
#> meanlog:
#> -1
#> sdlog:
#> 0.83We can then use this in the esimtate_infections()
function using the truncation option.
trunc <- estimate_infections(reported_cases,
generation_time = gt_opts(example_generation_time),
delays = delay_opts(delay),
truncation = trunc_opts(trunc_dist),
rt = rt_opts(prior = rt_prior)
)
# summarise results
summary(trunc)
#> measure estimate
#> <char> <char>
#> 1: New infections per day 3616 (2175 -- 6283)
#> 2: Expected change in reports Likely increasing
#> 3: Effective reproduction no. 1.1 (0.83 -- 1.3)
#> 4: Rate of growth 0.019 (-0.052 -- 0.096)
#> 5: Doubling/halving time (days) 37 (7.2 -- -13)
# elapsed time (in seconds)
get_elapsed_time(trunc$fit)
#> warmup sample
#> chain:1 35.054 14.061
#> chain:2 37.927 13.780
#> chain:3 34.316 11.011
#> chain:4 42.385 11.316
# summary plot
plot(trunc)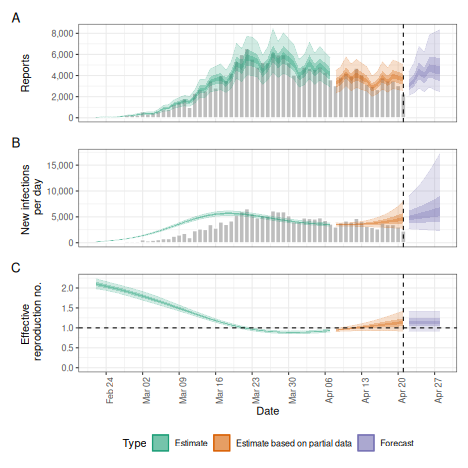
Projecting the reproduction number with the Gaussian Process
Instead of keeping the reproduction number fixed from a certain time point we might want to extrapolate the Gaussian Process into the future. This will lead to wider uncertainty, and the researcher should check whether this or fixing the reproduction number from an earlier is desirable.
project_rt <- estimate_infections(reported_cases,
generation_time = gt_opts(example_generation_time),
delays = delay_opts(delay),
rt = rt_opts(
prior = rt_prior, future = "project"
)
)
# summarise results
summary(project_rt)
#> measure estimate
#> <char> <char>
#> 1: New infections per day 2242 (1326 -- 3698)
#> 2: Expected change in reports Likely decreasing
#> 3: Effective reproduction no. 0.89 (0.69 -- 1.1)
#> 4: Rate of growth -0.029 (-0.1 -- 0.04)
#> 5: Doubling/halving time (days) -24 (17 -- -6.7)
# elapsed time (in seconds)
get_elapsed_time(project_rt$fit)
#> warmup sample
#> chain:1 41.058 19.471
#> chain:2 43.967 19.524
#> chain:3 37.837 18.635
#> chain:4 43.632 19.162
# summary plot
plot(project_rt)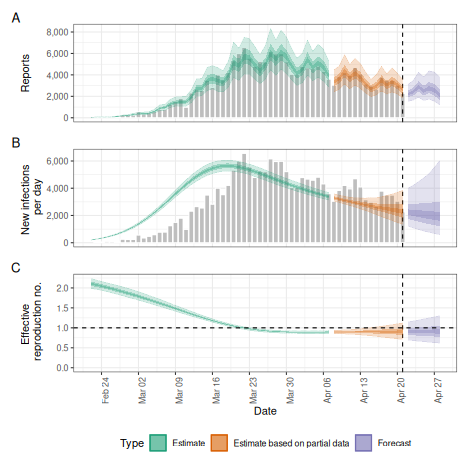
Fixed reproduction number
We might want to estimate a fixed reproduction number, i.e. assume that it does not change.
fixed <- estimate_infections(reported_cases,
generation_time = gt_opts(example_generation_time),
delays = delay_opts(delay),
gp = NULL
)
# summarise results
summary(fixed)
#> measure estimate
#> <char> <char>
#> 1: New infections per day 18916 (10905 -- 33106)
#> 2: Expected change in reports Increasing
#> 3: Effective reproduction no. 1.2 (1.2 -- 1.3)
#> 4: Rate of growth 0.053 (0.039 -- 0.068)
#> 5: Doubling/halving time (days) 13 (10 -- 18)
# elapsed time (in seconds)
get_elapsed_time(fixed$fit)
#> warmup sample
#> chain:1 3.318 1.570
#> chain:2 2.762 1.211
#> chain:3 3.490 1.312
#> chain:4 2.863 1.253
# summary plot
plot(fixed)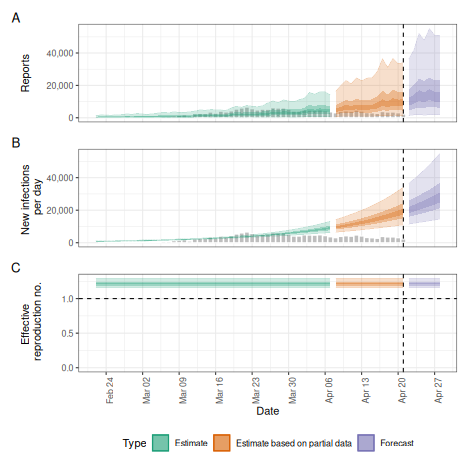
Breakpoints
Instead of assuming the reproduction number varies freely or is
fixed, we can assume that it is fixed but with breakpoints. This can be
done by adding a breakpoint column to the reported case
data set. e.g. if we think that the reproduction number was constant but
would like to allow it to change on the 16th of March 2020 we would
define a new case data set using
bp_cases <- data.table::copy(reported_cases)
bp_cases <- bp_cases[,
breakpoint := ifelse(date == as.Date("2020-03-16"), 1, 0)
]We then use this instead of reported_cases in the
estimate_infections() function:
bkp <- estimate_infections(bp_cases,
generation_time = gt_opts(example_generation_time),
delays = delay_opts(delay),
rt = rt_opts(prior = rt_prior),
gp = NULL
)
# summarise results
summary(bkp)
#> measure estimate
#> <char> <char>
#> 1: New infections per day 2318 (1946 -- 2737)
#> 2: Expected change in reports Decreasing
#> 3: Effective reproduction no. 0.9 (0.87 -- 0.92)
#> 4: Rate of growth -0.028 (-0.034 -- -0.022)
#> 5: Doubling/halving time (days) -25 (-32 -- -20)
# elapsed time (in seconds)
get_elapsed_time(bkp$fit)
#> warmup sample
#> chain:1 4.933 3.114
#> chain:2 4.343 2.582
#> chain:3 5.299 3.588
#> chain:4 4.492 3.115
# summary plot
plot(bkp)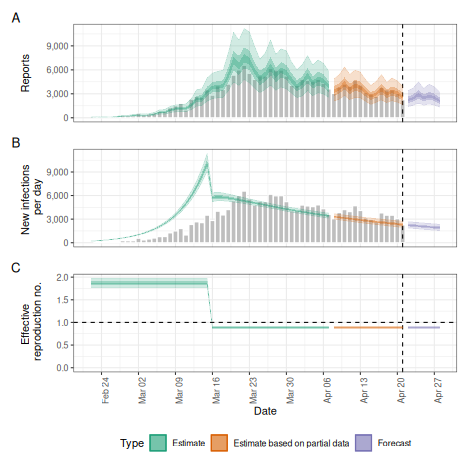
Weekly random walk
Instead of a smooth Gaussian Process we might want the reproduction
number to change step-wise, e.g. every week. This can be achieved using
the rw option which defines the length of the time step in
a random walk that the reproduction number is assumed to follow.
rw <- estimate_infections(reported_cases,
generation_time = gt_opts(example_generation_time),
delays = delay_opts(delay),
rt = rt_opts(prior = rt_prior, rw = 7),
gp = NULL
)
# summarise results
summary(rw)
#> measure estimate
#> <char> <char>
#> 1: New infections per day 1979 (1035 -- 3966)
#> 2: Expected change in reports Likely decreasing
#> 3: Effective reproduction no. 0.85 (0.61 -- 1.2)
#> 4: Rate of growth -0.042 (-0.11 -- 0.039)
#> 5: Doubling/halving time (days) -16 (18 -- -6.2)
# elapsed time (in seconds)
get_elapsed_time(rw$fit)
#> warmup sample
#> chain:1 14.165 10.353
#> chain:2 13.222 10.156
#> chain:3 13.717 10.345
#> chain:4 12.615 10.328
# summary plot
plot(rw)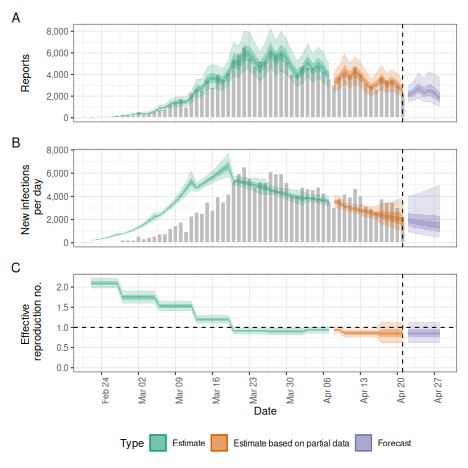
No delays
Whilst EpiNow2 allows the user to specify delays, it can also run directly on the data as does e.g. the EpiEstim package.
no_delay <- estimate_infections(
reported_cases,
generation_time = gt_opts(example_generation_time)
)
# summarise results
summary(no_delay)
#> measure estimate
#> <char> <char>
#> 1: New infections per day 2797 (2393 -- 3264)
#> 2: Expected change in reports Decreasing
#> 3: Effective reproduction no. 0.89 (0.8 -- 0.97)
#> 4: Rate of growth -0.031 (-0.064 -- -0.00013)
#> 5: Doubling/halving time (days) -22 (-5300 -- -11)
# elapsed time (in seconds)
get_elapsed_time(no_delay$fit)
#> warmup sample
#> chain:1 37.541 15.663
#> chain:2 43.454 14.085
#> chain:3 45.039 14.323
#> chain:4 36.880 16.695
# summary plot
plot(no_delay)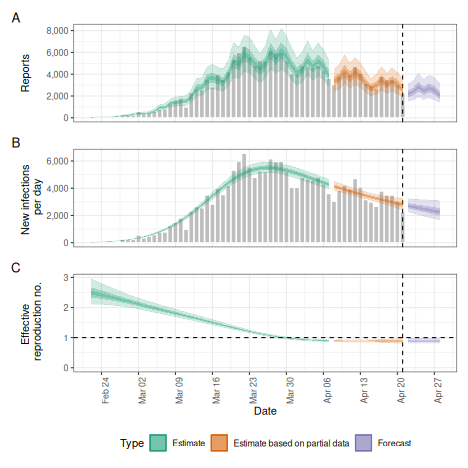
Non-parametric infection model
The package also includes a non-parametric infection model. This runs much faster but does not use the renewal equation to generate infections. Because of this none of the options defining the behaviour of the reproduction number are available in this case, limiting user choice and model generality. It also means that the model is questionable for forecasting, which is why were here set the predictive horizon to 0.
non_parametric <- estimate_infections(reported_cases,
generation_time = gt_opts(example_generation_time),
delays = delay_opts(delay),
rt = NULL,
backcalc = backcalc_opts(),
forecast = forecast_opts(horizon = 0)
)
# summarise results
summary(non_parametric)
#> measure estimate
#> <char> <char>
#> 1: New infections per day 2543 (2505 -- 2579)
#> 2: Expected change in reports Decreasing
#> 3: Effective reproduction no. 0.92 (0.83 -- 0.96)
#> 4: Rate of growth -0.024 (-0.025 -- -0.022)
#> 5: Doubling/halving time (days) -29 (-31 -- -28)
# elapsed time (in seconds)
get_elapsed_time(non_parametric$fit)
#> warmup sample
#> chain:1 4.091 0.641
#> chain:2 3.379 0.585
#> chain:3 4.167 0.630
#> chain:4 4.339 0.427
# summary plot
plot(non_parametric)