Get default metrics for sample-based forecasts
Source:R/class-forecast-sample.R
get_metrics.forecast_sample.RdFor sample-based forecasts, the default scoring rules are:
"crps" =
crps_sample()"overprediction" =
overprediction_sample()"underprediction" =
underprediction_sample()"dispersion" =
dispersion_sample()"log_score" =
logs_sample()"dss" =
dss_sample()"mad" =
mad_sample()"bias" =
bias_sample()"ae_median" =
ae_median_sample()"se_mean" =
se_mean_sample()
Usage
# S3 method for class 'forecast_sample'
get_metrics(x, select = NULL, exclude = NULL, ...)Arguments
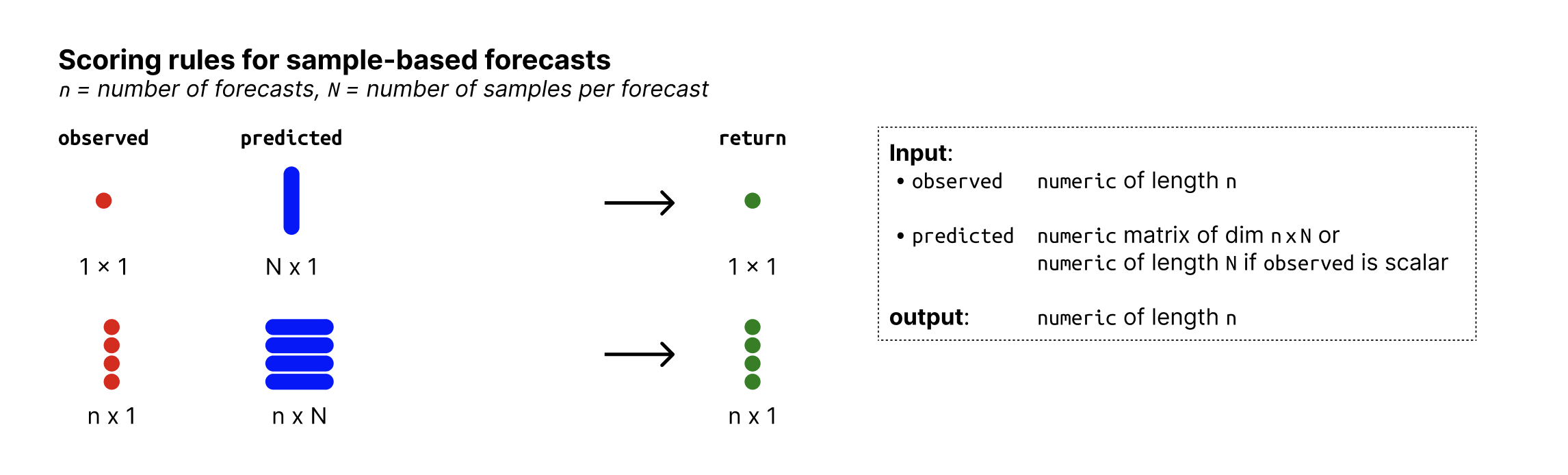
- x
A forecast object (a validated data.table with predicted and observed values, see
as_forecast_binary()).- select
A character vector of scoring rules to select from the list. If
selectisNULL(the default), all possible scoring rules are returned.- exclude
A character vector of scoring rules to exclude from the list. If
selectis notNULL, this argument is ignored.- ...
unused
See also
Other get_metrics functions:
get_metrics(),
get_metrics.forecast_binary(),
get_metrics.forecast_multivariate_point(),
get_metrics.forecast_multivariate_sample(),
get_metrics.forecast_nominal(),
get_metrics.forecast_ordinal(),
get_metrics.forecast_point(),
get_metrics.forecast_quantile(),
get_metrics.scores()
Examples
get_metrics(example_sample_continuous, exclude = "mad")
#> $bias
#> function (observed, predicted)
#> {
#> assert_input_sample(observed, predicted)
#> prediction_type <- get_type(predicted)
#> n_pred <- ncol(predicted)
#> if (prediction_type == "continuous") {
#> p_lt <- rowSums(predicted < observed)/n_pred
#> p_eq <- rowSums(predicted == observed)/n_pred
#> p_x <- p_lt + 0.5 * p_eq
#> res <- 1 - 2 * p_x
#> return(res)
#> }
#> else {
#> p_x <- rowSums(predicted <= observed)/n_pred
#> p_xm1 <- rowSums(predicted <= (observed - 1))/n_pred
#> res <- 1 - (p_x + p_xm1)
#> return(res)
#> }
#> }
#> <bytecode: 0x55b49e197d98>
#> <environment: namespace:scoringutils>
#>
#> $dss
#> function (observed, predicted, ...)
#> {
#> assert_input_sample(observed, predicted)
#> scoringRules::dss_sample(y = observed, dat = predicted, ...)
#> }
#> <bytecode: 0x55b4a480c050>
#> <environment: namespace:scoringutils>
#>
#> $crps
#> function (observed, predicted, separate_results = FALSE, ...)
#> {
#> assert_input_sample(observed, predicted)
#> crps <- scoringRules::crps_sample(y = observed, dat = predicted,
#> ...)
#> if (separate_results) {
#> if (is.null(dim(predicted))) {
#> dim(predicted) <- c(1, length(predicted))
#> }
#> medians <- apply(predicted, 1, median)
#> dispersion <- scoringRules::crps_sample(y = medians,
#> dat = predicted, ...)
#> difference <- crps - dispersion
#> overprediction <- fcase(observed < medians, difference,
#> default = 0)
#> underprediction <- fcase(observed > medians, difference,
#> default = 0)
#> return(list(crps = crps, dispersion = dispersion, underprediction = underprediction,
#> overprediction = overprediction))
#> }
#> else {
#> return(crps)
#> }
#> }
#> <bytecode: 0x55b4a60be470>
#> <environment: namespace:scoringutils>
#>
#> $overprediction
#> function (observed, predicted, ...)
#> {
#> crps <- crps_sample(observed, predicted, separate_results = TRUE,
#> ...)
#> return(crps$overprediction)
#> }
#> <bytecode: 0x55b4a6137810>
#> <environment: namespace:scoringutils>
#>
#> $underprediction
#> function (observed, predicted, ...)
#> {
#> crps <- crps_sample(observed, predicted, separate_results = TRUE,
#> ...)
#> return(crps$underprediction)
#> }
#> <bytecode: 0x55b4a6136ce8>
#> <environment: namespace:scoringutils>
#>
#> $dispersion
#> function (observed, predicted, ...)
#> {
#> crps <- crps_sample(observed, predicted, separate_results = TRUE,
#> ...)
#> return(crps$dispersion)
#> }
#> <bytecode: 0x55b4a61361c0>
#> <environment: namespace:scoringutils>
#>
#> $log_score
#> function (observed, predicted, ...)
#> {
#> assert_input_sample(observed, predicted)
#> if (get_type(predicted) == "integer") {
#> cli_warn(c("Predictions appear to be integer-valued.",
#> `!` = "The log score uses kernel density estimation, which may not be\n appropriate for integer-valued forecasts.",
#> i = "See the {.pkg scoringRules} package for alternatives for\n discrete probability distributions."))
#> }
#> scoringRules::logs_sample(y = observed, dat = predicted,
#> ...)
#> }
#> <bytecode: 0x55b4a21f20e8>
#> <environment: namespace:scoringutils>
#>
#> $ae_median
#> function (observed, predicted)
#> {
#> assert_input_sample(observed, predicted)
#> median_predictions <- apply(as.matrix(predicted), MARGIN = 1,
#> FUN = median)
#> ae_median <- abs(observed - median_predictions)
#> return(ae_median)
#> }
#> <bytecode: 0x55b49d356a88>
#> <environment: namespace:scoringutils>
#>
#> $se_mean
#> function (observed, predicted)
#> {
#> assert_input_sample(observed, predicted)
#> mean_predictions <- rowMeans(as.matrix(predicted))
#> se_mean <- (observed - mean_predictions)^2
#> return(se_mean)
#> }
#> <bytecode: 0x55b4a21f4120>
#> <environment: namespace:scoringutils>
#>