Estimates a truncation distribution from multiple snapshots of the same
data source over time. This distribution can then be passed to the
truncation argument in regional_epinow(), epinow(), and
estimate_infections() to adjust for truncated data and propagate the
uncertainty associated with data truncation into the estimates.
The model of truncation is as follows:
The truncation distribution can be any parametric family supported by
dist_spec(e.g. log-normal, gamma), with parameters informed by the data.The data set with the latest observations is adjusted for truncation using the truncation distribution.
Earlier data sets are recreated by applying the truncation distribution to the adjusted latest observations in the time period of the earlier data set. These data sets are then compared to the earlier observations using the selected observation model (negative binomial or Poisson) with an additive noise term to handle zero observations.
This can be thought of as a Bayesian form of the chain-ladder
nowcasting approach in the
baselinenowcast
package. For settings requiring time-varying delays, see
epinowcast.
Arguments
- data
A list of
<data.frame>s each containing adatevariable and aconfirm(numeric) variable. Each data set should be a snapshot of the reported data over time. All data sets must contain a complete vector of dates.- truncation
A call to
trunc_opts()defining the truncation of the observed data. Defaults totrunc_opts(), i.e. no truncation. See theestimate_truncation()help file for an approach to estimating this from data where thedistlist element returned byestimate_truncation()is used as thetruncationargument here, thereby propagating the uncertainty in the estimate.- obs
A list of observation model options as generated by
obs_opts(). The truncation model usesfamily,dispersion,likelihoodandreturn_likelihood. Other settings (weight,week_effect,scale) are ignored, since week effects and scaling are not modelled here. Defaults toobs_opts().- noise
A
dist_specspecifying the prior on the additive noise term applied to expected observations. This small positive offset prevents zero expected counts. Defaults toNormal(mean = 0, sd = 1)with a lower bound of zero (i.e. a half-normal prior).- stan
A list of stan options as generated by
stan_opts(). Defaults tostan_opts(). Can be used to overridedata,init, andverbosesettings if desired.- CrIs
Numeric vector of credible intervals to calculate.
- filter_leading_zeros
Logical, defaults to FALSE. Should zeros at the start of the time series be filtered out.
- zero_threshold
Numeric, defaults to Inf. Observations with a primary count less than this threshold are set to zero.
- verbose
Logical, should model fitting progress be returned.
- ...
Additional parameters to pass to
rstan::sampling().
Value
An <estimate_truncation> object containing:
observations: The input data (list of<data.frame>s).args: A list of arguments used for fitting (stan data).fit: The stan fit object.
Examples
# \donttest{
# set number of cores to use
old_opts <- options()
options(mc.cores = ifelse(interactive(), 4, 1))
# fit model to example data
# See [example_truncated] for more details
# iterations and calculation time have been reduced for this example
# for real analyses, use more
est <- estimate_truncation(example_truncated,
verbose = interactive(),
chains = 2, iter = 200
)
# extract the estimated truncation distribution
get_parameters(est)[["truncation"]]
#> - lognormal distribution (max: 10):
#> meanlog:
#> - normal distribution:
#> mean:
#> 0.9
#> sd:
#> 0.005
#> sdlog:
#> - normal distribution:
#> mean:
#> 0.6
#> sd:
#> 0.006
# summarise the truncation distribution parameters
summary(est)
#> Truncation distribution: lognormal (max: 10)
#>
#> Parameter estimates:
#> variable median mean sd lower_90 lower_50 lower_20
#> <char> <num> <num> <num> <num> <num> <num>
#> 1: meanlog 0.9007391 0.9005145 0.005032068 0.8923784 0.8970311 0.8992350
#> 2: sdlog 0.5992927 0.5991649 0.006286597 0.5886394 0.5948613 0.5975564
#> upper_20 upper_50 upper_90
#> <num> <num> <num>
#> 1: 0.9018049 0.9039662 0.9085548
#> 2: 0.6008305 0.6034651 0.6095034
# validation plot of observations vs estimates
plot(est)
#> Ignoring unknown labels:
#> • fill : "Type"
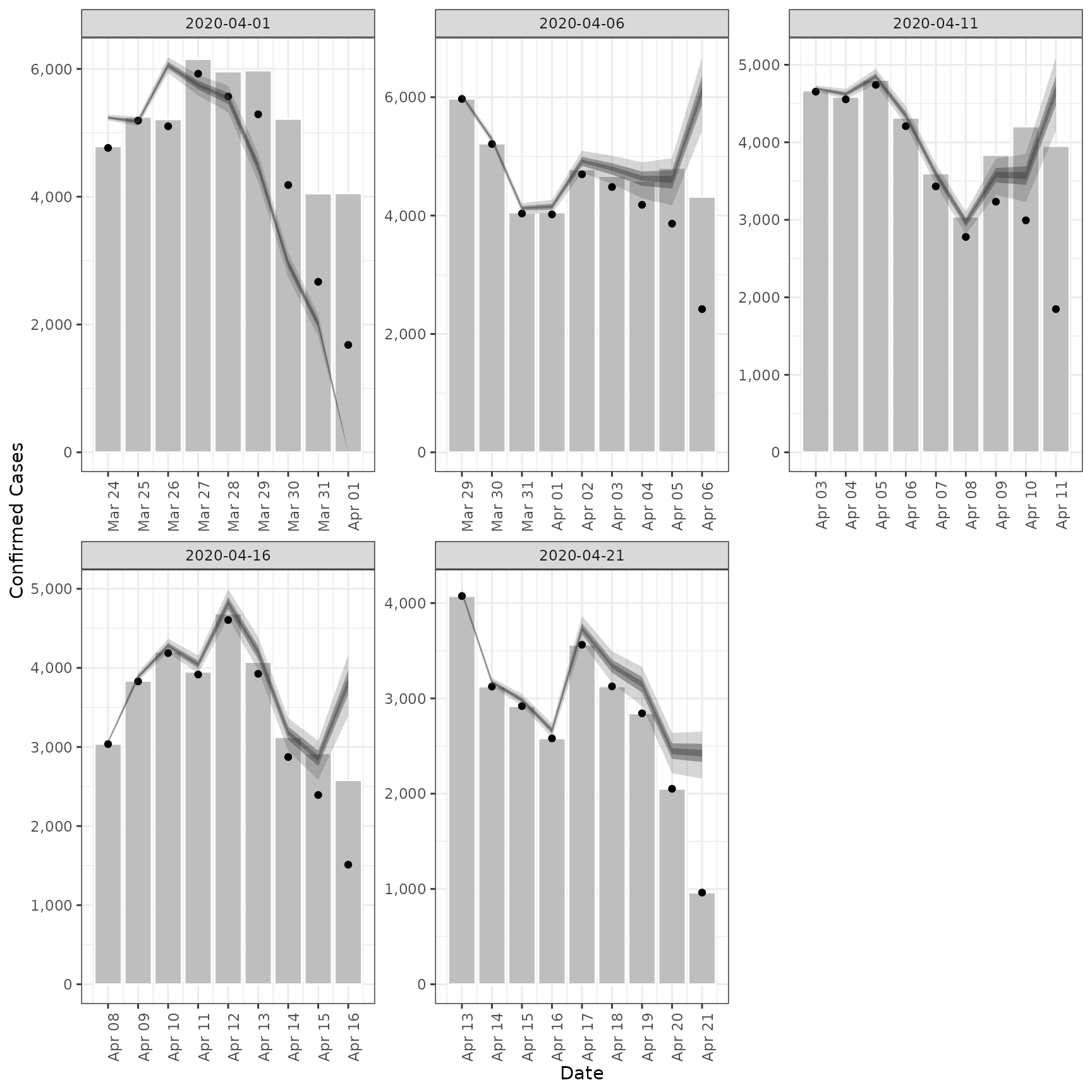 # Pass the truncation distribution to `epinow()`.
# Note, we're using the last snapshot as the observed data as it contains
# all the previous snapshots. Also, we're using the default options for
# illustrative purposes only.
out <- epinow(
generation_time = generation_time_opts(example_generation_time),
example_truncated[[5]],
truncation = trunc_opts(get_parameters(est)[["truncation"]])
)
#> Logging threshold set at INFO for the name logger
#> Writing EpiNow2 logs to the console and:
#> /tmp/Rtmpq2JtQ6/regional-epinow/2020-04-21.log.
#> Logging threshold set at INFO for the name logger
#> Writing EpiNow2.epinow logs to the console and:
#> /tmp/Rtmpq2JtQ6/epinow/2020-04-21.log.
plot(out)
# Pass the truncation distribution to `epinow()`.
# Note, we're using the last snapshot as the observed data as it contains
# all the previous snapshots. Also, we're using the default options for
# illustrative purposes only.
out <- epinow(
generation_time = generation_time_opts(example_generation_time),
example_truncated[[5]],
truncation = trunc_opts(get_parameters(est)[["truncation"]])
)
#> Logging threshold set at INFO for the name logger
#> Writing EpiNow2 logs to the console and:
#> /tmp/Rtmpq2JtQ6/regional-epinow/2020-04-21.log.
#> Logging threshold set at INFO for the name logger
#> Writing EpiNow2.epinow logs to the console and:
#> /tmp/Rtmpq2JtQ6/epinow/2020-04-21.log.
plot(out)
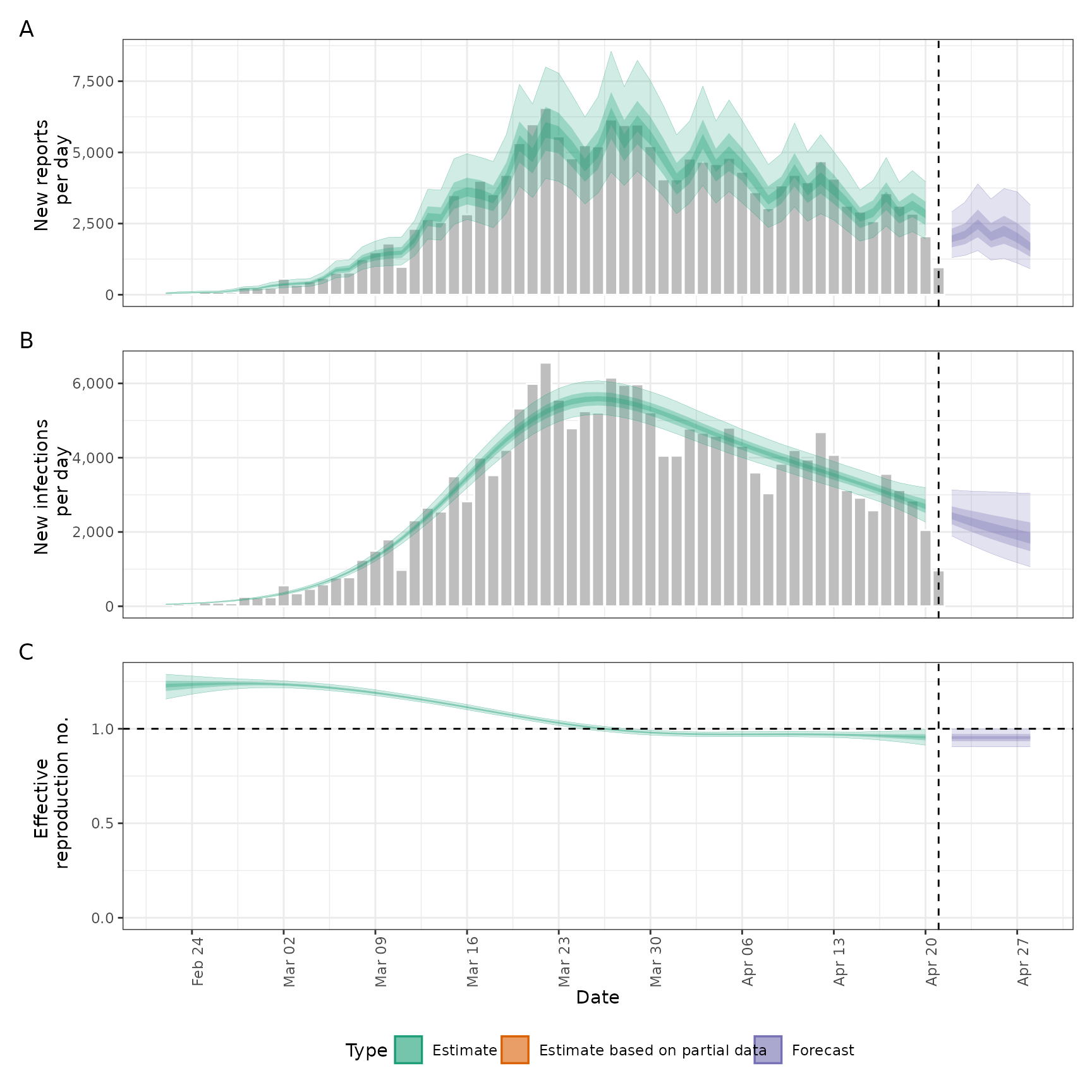 options(old_opts)
# }
options(old_opts)
# }